The Rusty Web
Last Update: 11 Jan 2014
This is a meditation on information, time, and the patina of the Web.
It began as a set of notes from a talk prepared in open collaboration with my old friend and collaborator Karl Dubost. It was originally presented (in French) to the audience of the Paris Web 2013 Conference, and then in several anglophone venues, notably a number of internal talks for BBC Future Media.
It is a work in progress.

Served by Siddharta. London. August 2011, 18:34.
"Do you want the receipt in the bag? " she asks.
Yes please. I might need the receipt — having to walk through the whole supermarket to reach the exit at the other end, and Im always wondering whether some day they will stop me there and ask to prove I haven't dropped a can of beans or a bar of chocolate into my bag on the way through the aisles. The receipt, right here and right now, is an integral part of the social contract of trust between me and the shop.
At the bottom of the receipt is written "retain for your records". And indeed, through the next minutes, hours, weeks and years, the information encoded on this small slip of paper may be useful to me, and to others, in many different ways.
For now, it is a way for me to prove that I have indeed paid for the groceries. In a few days, I could use it to return an unwanted item; in a month, I can compare it to a line on my bank statement; within the year it could be the proof of purchase I use to claim warranty on the unreliable battery charger.
Beyond that, it gets blurry: in theory, this could be used in months or years by a trash-digging detective to detect patterns in my lifestyle; by a late 21st-century sociologist to study the cost of living and typical lifestyle of a middle-class male in 2013; or by a 40st-century archeologist to understand life in Europe at the turn of the millennium.
Of course, they won't: even if I kept in a metal box for the rest of my life, the low quality of the ink and paper used would certainly make the receipt unreadable and unusable within a few years. Someone, at some point, made choices about the technology of the grocery receipt on behalf of the provider and the (known and yet unknown) possible users of the information.
Whoever designed this physical manifestation of the information about this transaction between the shop and I has decided that the short-term uses of the receipt are valid, but they did not deem archaeology to be a reasonable use case, and thus decided that a transient design for this receipt was acceptable. It might be a pity that this receipt is unlikely to be the rosetta stone of the 40th century; at least I don't have to carry a carved piece of stone in my wallet.
And I tend to shred all my receipts anyway.

Infobesity is beautiful
Whenever anyone talks about information and time, the cliché generally goes that we are in the midst of an "explosion of information". Some agree, others dissmiss: there are documented examples, throughout history, of old curmudgeons complaining about information overload or lamenting the advent of new technology which will obviously turn our finely honed brains to mush, from writing (was it Socrates who thought it a terrible substitute to oral memory?) to the web and search engines at the tip of a finger.
What is true: we are recording more information than ever. Thus was coined the term infobesity, from information and obesity. The term is obviously loaded with judgement about whether we, as individuals or as a society, should really be storing and keeping so much information about what we all do, see and think. This denotes an underlying belief that there are several types of information, roughly split between throwaway information and valuable information.
This value judgement is worth a bit of scrutiny.
Assuming that indeed some information is more valuable than others, how do we determine the value of information. There is, as far as I know, no clear framework to score or rank the value of a piece of information. Information does derive value from the use we can make of it - commercial, educational, emotional - but the diversity of usage means that the value can be fiduciary just as well as it can be sentimental.

Choice
And there lies a difficult question.
Information, as the currency of our postmodern era proves to be of a very subjective value. There will be unavoidable disagreement as to whether a piece of information is "worth keeping" (and for how long) or throwaway. It is enough of a debate for my inner multitude when it comes to keeping old notebooks, but in a connected world where the producers, mediators and hosts of information are all different actors with different goals and sometimes incompatible value systems, who decides what to keep and how long becomes a battlefield.
Hence - social networking sites keeping my information for as long as they exist, for which I may be grateful if I consider them an externalised but valuable part of my memory. But if I want to consider it a transient stream of consciousness and social interactions? Tough luck for those without the technical chops to build a software solution to delete and keep a personal archive of this social stream.
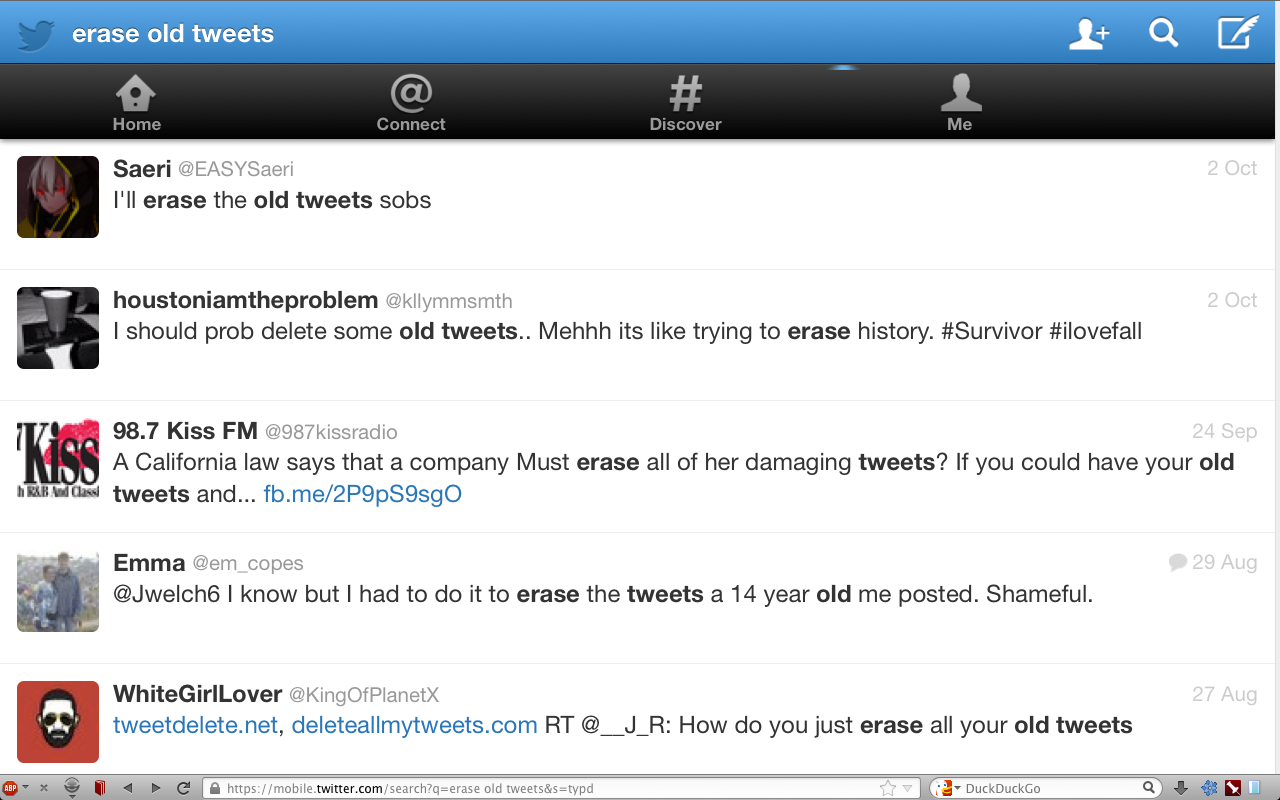
Searching Twitter for "Erase old tweets", October 2013
Think also of a recent bill in California which would force all internet services to offer an option to erase the digital past of individuals coming of age at 18.
Conversely, consider whether the fact that you have been hosting content (for free, for years) gives you the right to decide to wipe content off the web with only a modicum of advance warning. Yahoo did it for the web-ancient Geocities hosting platform. Most of the world cared little; yet parts of the community found it to be an unacceptable massacre, and salvaged what they could into OOCities.
And now it’s interesting to see a new crop of services such as SnapChat where a commitment on the shelf life of information is the central value proposition.

The artisan's toolbox
For the rest of us who don’t design services to autodestruct content after a few seconds, there is the question of how you manage the information over time. The question is especially important when we work on the generally ill-named "redesigns" of web sites. The term "refonte", often used in French, is probably more accurate in describing the standard practice: melt everything away and forge anew.
Indeed, the issue with web redesigns is that they are seldom only about a tweak to the visual presentation of information or interaction - in an craft where separation of content and style is the contemporary norm, that would be a reasonably easy thing to do. But the rather unfrequent nature of the redesigns imply that they will come with a change of technical platform, with different templates, identifiers for information, a different visible footprint of technology, and so on.
Our craft is evolving, and we are starting to have a set of good practices and tools at our disposal: a better understanding of HTTP redirection and error messages (although I am yet to see anyone do anything really useful with the unloved 410 Gone), smarter management of URL (hide your shame, child, hide those technology-dependent extensions already!).

Dates matter
Among billions of sentences written on the web in the present tense, most will become untrue sooner or later. Some will become significant witnesses of their time - others will simply keep being liars until they disappear. The difference, I believe, is as simple as it is powerful: some content is clearly dated - ideally with public visibility over when it was created, updated, and, heck, by whom. Others just state things in a context vacuum.
Tagging a date to a piece of information matters. It may well be the simplest, yet most important way of acknowledging that the nature and usage of information changes over time, and to design our services accordingly. And since there will be disagreement as to how the usefulness of information will evolve over time, the least we can do is be transparent about our choices, whatever they are.
For instance: craft a persistence policy for your web sites or services. An organisation like the W3C has a very public policy pledging substantial efforts to make resources on the www.w3.org Web site persistent.
This is not just a matter for organisations - at a personal level, I have made (and documented) my persistence preference on some online services as well as on my website, where I tend to make an effort to update all the pages whenever I "redesign", whatever the cost. Karl, on the other hand, has decided to keep every page as-is when he changes the look of his site. Wandering through his archives, one can see how the site was in 2000, 2005 or 2010, each page a faithful witness of its time.

Preservation, information and technology
Sometimes, however, the choice is not ours. I already hinted at it in earlier examples, but more often than not, the author or caretaker of a piece of information is not the right person to make the right choice about its preservation. People, organisations, stop caring, or die. There is even an early movement towards "digital wills".
So: how do we preserve a web site (or indeed, the web as a whole) for the ages? Lawmakers have decided it is important. Archivists are working at it. And finding it really, really hard.
Part of what makes it so complicated is the layering of technology: are we preserving "content", "pages", system, or the knowledge of the platform? Or a mix, maybe?

Put the web in a jar and hope it pickles well
The other, more pernicious problem in my opinion is that the archivist's model, albeit useful, is too limited and not adapted to digital nature of web.
Archivists are used to preserving artefacts, or at best "dead" instances of information. Want to preserve an object? Put it in a box, protect it from air and light. Preserving a book or a periodical can be the same thing, but you can also make a copy of it on a medium which you deem to be less fragile (e.g. microfilm).
But you can't do that with the web. The web is big, almost unfathomable, and it is ever-changing. You can't put an experience in a box, shielded from the corrosion of air and light. And the closest thing to preserving a living thing is mummifying or taxidermy, and it is not quite the real thing. That is exactly what web archivists are facing.
That’s why a number of us have started thinking about a different model of preservation.

Replicate, evolve
And yet, there is a way to preserve living things: replication, multiplication, and eventually, evolution. Such a genetic model is a particularly interesting metaphor to explore when thinking of the web. Very much like DNA, digital information can be copied for free, replicated almost without error.
Hence a new model of preservation for the web, complementary to the "black box" approach of the archivist, and more intent on preserving the web as a living, diverse ecosystem of ideas and methods than on preserving an almost exact snapshot of it at a given point in time.
The digital curator then engages in a digital "Panda breeding program" – a term coined by the team at the Cooper-Hewitt design Museum as they decided to preserve a digital application by opening its source code. Identify the life forms which we'd like to see survive the ages, and give it a chance to do so.

Part of my ever-expanding collection of "no photo" signs in photography exhibition or other photo-related locales. None of which see any irony whatsoever in their rules.
As producers or creators of information, we have a role to play in such a "genetic" preservation of what we bring to the world. Given the ever-expanding and strict frameworks of copyright, do we want to keep all that information and creation "Copyright-all-rights-reserved-no-touchy-or-else" forever and ever, or at least long after we've stopped caring?
Licenses, and their changes through time, should be part of our design of information. We should be thinking about how and when and whether to open our web information so that others can participate in its preservation/evolution.
Not that I am suggesting that everything should be in the public domain always and forever and by default: such a scenario will enchant some, horrify others. But anyone caring about their contribution to the web should probably think very hard about how and when copyright protects or hinders, and how and when more liberal frameworks such as the array of Creative Commons licenses jeopardises business or enables preservation.

Patina and Rust
Keeping too tight a grip on copyright may indeed well result in a web that rusts, that just sits there, unused, unlinked and unliked. A dead wart on a living medium. Or maybe a dried, pickled plum in a jar. Which may be nice if that is what you are after.
I prefer to dream of a web with a lovely patina, gained through the years and aeons.
Sadly, I seem to disagree with pretty much everyone on what constitutes the "patina of the web".
It is natural to think of visual manifestations when we think of the concept of "patina". This is how patina manifests itself: the polish of a thousand grips on a handle, the swipe of a hundred brushes on leather. And so, when it comes to applying the concept of patina to our digital medium of choice, we tend to try and apply similar visual cues: fading images, yellowing pages.

Memory of use
That might be a fairly successful trigger of pseudo-nostalgia, but it certainly isn't patina.And so, how glad I was to find recent studies showing user reject the artificial ageing/patina of the web. (see e.g. "Digital Artifacts as Legacy: Exploring the Lifespan and Value of Digital Data", Gulotta, Odom et.al. - CHI'2013)
Let us get away from "yellowing paper" and "vintage filters", and need to define a digital "native" notion of web patina. And the only viable way to do so is to use a different definition of patina: "the memory of usage".
And what is the memory of usage on the web? It is not the slightly quaint visual design of the 1990s. But it may well be that the patina of the web, similarly to the layers of oil from countless hands, manifests itself as layers of interaction, information accumulating over time.
I like to think of Wikipedia, with its articles edited over time by many hands, or the ever-expanding universe of links or commentary around many "viral" internet phenomena to be valid examples of truly digital patina.
All this to say: time changes all, even the web, especially the web. Whether we want it or not. Information left unchanged as cold dead bits frozen in a given state will rust. And the web will keep on living, evolving, sometimes gathering digital patina where billions of hypertext pointer-hands will have brushed against it. There is ultimate beauty in the impermanent.
And so: let us strive to not only embrace the impermanence of our medium, but also to better understand how time affects it and know when to work with, for, or around that impermanence.

Beauty in the impermanent
This is a conversation. One, ultimately, started by Tim Berners-Lee when he invented the web, or when he thundered that Cool URIs don't change. It owes a lot to a few thinkers and practitioners of the web, famous or not, each tackling the question from a different angle. To the librarians and archivists of the Internet Archive and other organisations tackling the question of the legal deposit of digital artefacts. To Mark Boulton and his reflections on Digital Patina, to Stephanie Troeth and her musings on bringing the aesthetics of impermanence to our medium.
This article features some of my photos, alongside several lovely ones by Karl Dubost. They are published here under a Creative Commons CC-by 4.0 License.
Previous/Next
Travel in the 21st Century
2013-11-24

Welcome to 21st century, where travel isn't so much adventure, more like a pesky phase transition.
Chiuso Per Ferie
2014-03-29

Florence, Aout 2013. Les locaux ont déguerpi, il reste quelques milliers de touristes, quelques siècles d'histoire.